Частина 20 - Обробка інструкцій
Для повного змісту змісту всіх уроків натисніть нижче, оскільки це надасть вам короткий зміст кожного уроку, а також теми, які будуть розглянуті. https://github.com/mytechnotalent/Reverse-Engineering-Tutorial
Процесор читає інструкційні коди, які зберігаються в пам'яті, оскільки кожен кодовий набір може містити один або кілька байтів інформації, які вказують процесору виконувати дуже спеціальну операцію. Коли кожен інструкційний код читає з пам'яті, необхідні дані для інструкційного коду також зберігаються і читає з пам'яті. Увага, пам'ять, яка містить інструкційні коди, не відрізняється від байтів, які містять дані, використовувані процесором, і спеціальні вказівники використовуються для допомоги процесору тримати в пам'яті дані і де зберігаються інструкційні коди. Інформаційний вказівник допомагає процесору тримати в пам'яті, де починається область даних в пам'яті, яка називається стеком. Коли нові елементи даних розміщуються в стеку, вказівник стека рухається вниз в пам'яті, а коли дані читаються з стека, вказівник стека рухається вгору в пам'яті. Будь ласка, перегляньте Частина 15 – Стек, якщо ви не розумієте цього поняття. Інформаційний вказівник використовується для допомоги процесору тримати в пам'яті, які інструкційні коди вже були оброблені і який код повинен бути оброблений далі. Будь ласка, перегляньте Частина 12 – Інформаційний вказівник реєстру, якщо ви не розумієте цього поняття. Кожен інструкційний код повинен містити opcode, який визначає основну функцію або завдання, яке виконує процесор, до якого операнди знаходяться між 1 і 3 байтами в довжині і унікально визначають функцію, яка виконується. Давайте розглянемо простий програмний код на мові C, який називається test.c, щоб розпочати роботу.
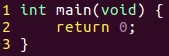
Усі, чого ми робимо, це створюємо функцію головного типу цілого, до якої він має параметр void і повертає 0. Усі цей програма робить лише просто виходити з ОС. Давайте скомпілюємо і запустимо цей програму.

Давайте використаємо objdump інструмент і знайти функцію головного в ньому.

Показані нижче результати, які ви отримаєте, виконавши попередній команду.
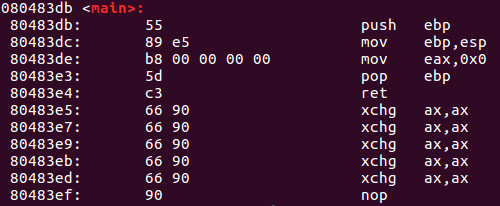
У лівій частині ми бачимо відповідні адреси пам'яті. У центрі ми бачимо операнди, а на правій стороні ми бачимо відповідну мову збірки в Інтел-синтаксі. Для простоти, давайте розглянемо адресу пам'яті 80483de, де ми бачимо операнди b8 00 00 00 00. Ми бачимо, що b8 opcode відповідає mov eax, 0x0 інструкції на правій стороні. Наступна серія 00 00 00 00 представляє 4 байти значення 0. Ми бачимо mov eax, 0x0, тому значення 0 переміщується в eax, тому представляє вищезгаданий код. Пам'ятайте, платформа IA-32 використовує наші little-endian запис, який означає, що нижчі байти з'являються першими при читанні зліва направо. Я хочу переконатися, що ви добре розумієте це, тому давайте уявімо, що значення вище було:
mov eax, 0x1
У цьому сценарії відповідний opcode був би:
b8 01 00 00 00
Якщо ви заплуталися, не хвилюйтеся. Пам'ятайте little-endian? Пам'ятайте, що eax має ширину 32 біти, тобто 4 байти (8 біт = 1 байт). Значення перелічені у зворотньому порядку, тому ви бачите вище представлення. Я чекаю побачити вас усіх наступної тижня, коли ми вийдемо на глибину деталей про те, як скомпільовувати програму.