Частина 22 - Програма ASM 1 [Moving Immediate Data]
Для повного змісту змісту всіх уроків, будь ласка, натисніть нижче, оскільки це надасть вам короткий зміст кожного уроку, а також теми, які будуть розглянуті. https://github.com/mytechnotalent/Reverse-Engineering-Tutorial
Я вдячний кожному, хто був терпеливим, оскільки для створення першої програми ASM потрібно було 21 урок, проте дуже необхідна підготовка мала бути виконана, щоб повністю зрозуміти, звідки починаємо, коли розробляємо мову збірки. Ми створимо 32-бітові програми мовою збірки, оскільки більшість шкідливого програмного забезпечення написано в 32-бітовому режимі для атаки на найбільшу кількість систем можливих. Увага! Хоча більшість з нас всі мають 64-бітові операційні системи, 32-бітові програми можуть працювати на них. На більшій частині ми працювали з Інтел-синтаксисом, коли мова йшла про мову збірки, проте я буду фокусуватися на нативній AT&T-синтаксисі далі. Це дуже легко перетворювати між Інтел-синтаксисом і AT&T-синтаксисом, як я продемонстрував раніше. кожна програма мови збірки розділена на три частини:
1)Дані Секція: Ця частина використовується для оголошення ініціалізованих даних або констант, оскільки дані ніколи не змінюються під час виконання. Ви можете оголошувати константні значення, розміри буфера, імена тощо. 2)Секція BSS: Ця частина використовується для оголошення неініціалізованих даних або змінних. 3)Текстова Секція: Ця частина використовується для справжніх секцій коду, оскільки вона починається з глобальної _start, яка вказує ядро, звідки починається виконання. Критично для будь-якої розробки є використання коментарів. У AT&T-синтаксисі ми використовуємо # символ для оголошення коментаря, оскільки будь-які дані після цього символу на відповідній лінії будуть проігноровані компілятором. Увага! Мови збірки мають такі особливості: вони мають одне ствердження на рядок, оскільки ви не повинні закінчувати рядок крапкою з комою, як у багатьох інших мовах. Структура ствердження така:
[label] mnemonic [operands] [comment]
Базовий інструкція має дві частини, з яких перша частина — це назва інструкції або мніміфікатор, який виконує інструкцію, а друга частина — це операнди або параметри команди. Перша наша програма продемонструє, як перемістити миттєві дані в регістр і миттєві дані в пам'ять. Давайте відкриємо VIM і створимо програму під назвою moving_immediate_data.s і введемо наступне:
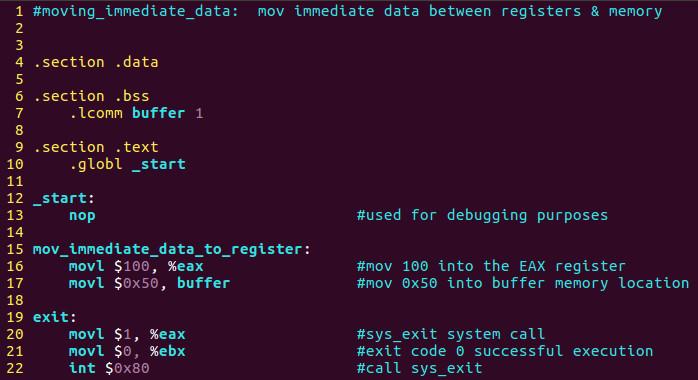
Для компіляції введіть:
as –32 -o moving_immediate_data.o moving_immediate_data.s
ld -m elfMDXX_i386XMDX -o moving_immediate_data moving_immediate_data.o
Для виконання введіть:
./moving_immediate_data
Я хотів би показати вам, як воно виглядає в Інтел-синтаксисі також. Перед тим, як ми розглянемо цю частину, вам потрібно буде ввести в командному вікні sudo apt-get install nasm, що встановить Netwide Assembler:
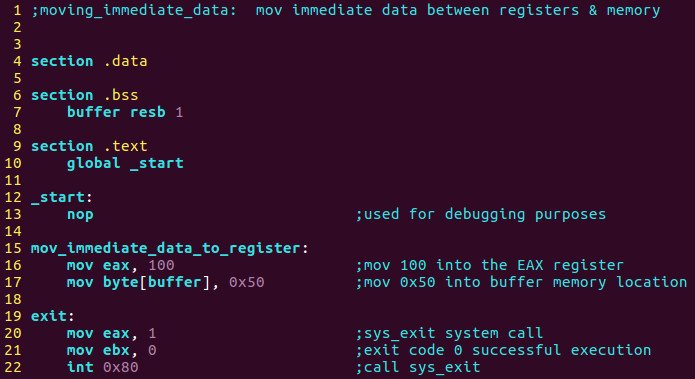
Для компіляції ви повинні ввести:
nasm -f elf32 moving_immediate_data.asm
ld -m elfMDXX_i386XMDX -o moving_immediate_data moving_immediate_data.o
Для виконання потрібно ввести:
./moving_immediate_data
Що ж до цього! Ні, немає ніякої інформації! Це правильно, і ви нічого не робили неправильно. Багато наших програм не будуть виконувати ніякої дії, оскільки вони майже нічого не роблять, окрім того, що будуть використовуватися в GDB для аналізу та маніпулювання. Наступна неділя ми виведемо GNU GDB-дебагер і побачимо, що відбувається під капотом. Я хочу трохи часу, щоб обговорити код на рядках 20-22 в версії AT&T і Intel Syntax. Ця група інструкцій використовує переваги, які ми call отримали шляхом використання програмного переривання. На рядку 20 в AT&T Syntax ми маємо movl $1, %eax meaning we move the decimal value of 1 into eax which specifies the sys_exit call which will properly terminate program execution back to Linux so that there is no segmentation fault. On line 21, we movl $0, %ebx, яка переміщує 0 в ebx, щоб показати, що програма успішно виконувалася, і нарешті ми бачимо int $0x80. Рядки 20 і 21 встановлюють програмне переривання, яке ми використовуємо на рядку 22 з інструкцією int $0x80. Давайте трохи глибше виведемо цей матеріал. У Linux існують дві окремі області пам'яті. На дуже нижній частині пам'яті під час виконання програми ми маємо Кернерний простір, який складається з секції Dispatcher і Векторної таблиці. На дуже верхній частині пам'яті під час виконання програми ми маємо Простір користувача, який складається з Стека, Хвоста і, нарешті, вашого коду, який можна ілюструвати нижче діаграмою:
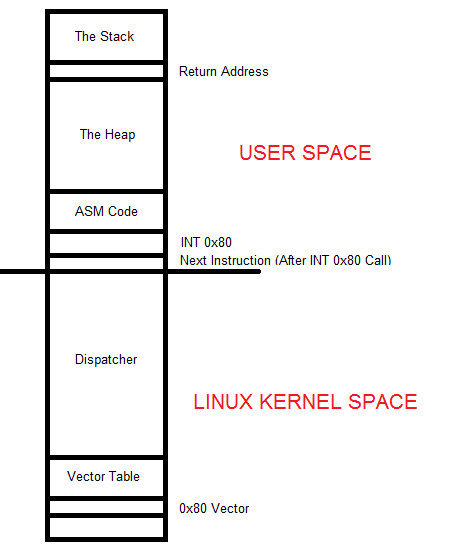
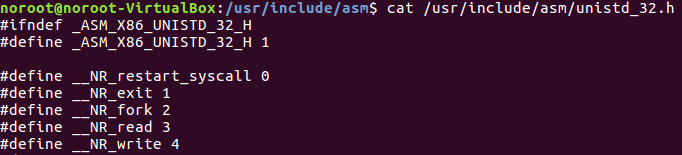
Коли ми завантажуємо значення, як ми показали раніше, call INT 0x80, наступна інструкція адреса в Просторі користувача, секції коду ASM, яка є вашим кодом, розміщується в області Повернення адреси в Стеку. Це дуже важливо, щоб коли INT 0x80 виконує своє завдання, воно може належним чином знати, яку інструкцію потрібно виконувати далі, щоб забезпечити належну і послідовну виконання програми. Увага! У сучасних версіях Linux ми використовуємо Захищений режим, що означає, що ви не маєте доступу до Кернерного простору Linux. Всі речі під довгою лінією, яка проходить посередині діаграми вище, представляють Кернерний простір Linux. Природжена питання — чому ми не можемо отримати доступ до цього? Відповідь дуже проста: Linux не дозволяє вашому коду отримувати доступ до внутрішніх операційної системи, оскільки це дуже небезпечно, оскільки будь-яке шкідливе програмне забезпечення може маніпулювати цими компонентами OS, щоб відслідковувати всі види діяльності користувача, такі як натиснення клавіш, тощо. Крім того, сучасна архітектура Linux змінює адреси цих ключових компонентів постійно, коли встановлюються нові програми і видаляються, а також під час системних оновлень. Цей є основою системи управління захищеним режимом. Наш спосіб спілкування між кодом та ядром Linux відбувається через використання служби ядра call3, яка є захищеним гейтвей між простором користувача, де ваша програма працює, та простором ядра, який реалізований через Linux Software Interrupt 0x80. На дуже глибокій частині пам'яті, де існує сегмент 0, офсет 0, знаходиться таблиця пошуку із 256 записів. Кожен запис містить адресу пам'яті, яка складається із сегмента та офсета, які займають по 4 байти кожен. Перші 1024 байти відведені під цю таблицю, а ніякий інший код не може бути змінений там. Кожна адреса називається вектором переривання, який складається із всього вектора переривання, де кожен вектор має номер від 0 до 255, а вектор 0 починається з зайняттям байтів 0-3. Цей процес продовжується далі, починаючи з вектора 1, який містить байти 4-7 тощо. Пам'ятайте, що жодна з цих адрес не належить постійній пам'яті. Статичним є вектор 0x80, який вказує на диспетчер послуг, який вказує на служби ядра Linux. Коли адреса повернення видаляється зі стека, виконання програми продовжується далі, а інструкція називається Переривання Повернення або IRET, яка завершує виконання програми. Вийдіть трохи часу та перегляньте всю таблицю системних викликів, відкривши термінал та натиснувши:
cat /usr/include/asm/unistd_32.h
Нижче наведено знімок лише декількох з них. Як бачите, exit 1 представляє sys_exit, який ми використовували у своєму попередньому коді.
З цього уроку ми розпочнемо 3-ступінчастий підхід:
1)Програмування
2)Дебагування
3)Хакінг
Кожна неділя ми розпочнемо з програми, яку ви бачите тут, наступну неділю ми візьмемо її та дослідимо, що саме відбувається на рівні асемблера, а на третьому етапі кожного тижня ми змінюватимемо дані в GDB, змінюючи їх на те, чого ми хочемо, демонструючи можливість контролювати виконання програми, яка включає навчання, як хакнути віруси до того, як вони не будуть загрозою. Ми не обов'язково розглянемо віруси прямо, оскільки я краще фокусуюся на теми програми на мові асемблера, які нададуть вам інструменти та розуміння, щоб будь-яка програма могла бути відлагоджена та змінена за бажанням. Це мета цих навчальних матеріалів. Інформація, яку ви навчитеся в цій серії навчальних матеріалів, може бути використана з високорівневими GUI-дебагерами, як IDA Pro, але я фокусуватимуся лише на GNU GDB-дебагері!